도움받은 사이트 :
https://developer.zebra.com/thread/34694
https://stackoverflow.com/questions/68627676/c-sharp-zebra-hex-compress-algorithm
Zebra ZPL 에서 GFA 명령어는 이미지를 라벨에 출력할 때 사용하는 Command 이다.
labelary 사이트에서 간단히 가져다 쓸 수도 있지만
최대한 개념을 익히는 방향으로 글을 쓴다.
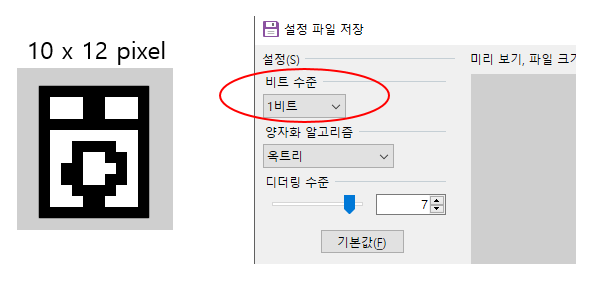
♣ BMP 파일 생성
테스트를 위해 BMP 파일을 하나 만든다.
Zebra 프린터의 경우, 흑백으로 출력하기에 BMP 저장 시, 1비트로 저장한다.
아래는 Paint.net (무료) 이라는 이미지툴에서 아래처럼 적당히 이미지를 만들고,
1비트로 저장하는 예시이다.
디더링 수준은 테스트 결과, 무시해도 된다.
♣ Labelary 사이트에서 GFA 데이터 얻기
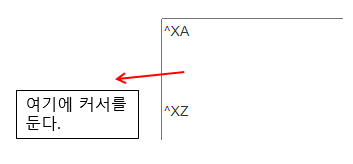
1. Labelary 사이트에 접속한다. ( Link : https://labelary.com/viewer.html )
2. 아래처럼 ZPL 코드창에 ^XA ^XZ 명령어를 입력한다.
3. 위와 같이 커서를 두고, Add Image 버튼을 눌러 위에서 생성한 BMP 파일을 부르면,
아래처럼 GFA 코드를 생성한다.
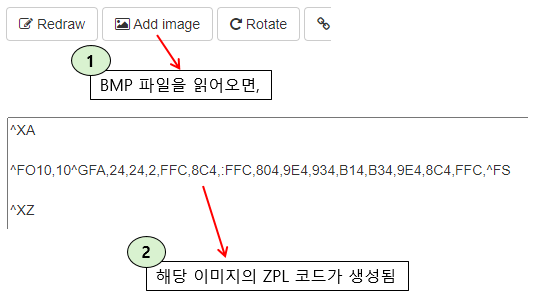
4. 이제 위에 생성된 코드값을 적절히 사용하면 된다.
5. 끝 ㅋㅋ~
6. 이제 나가세요. ㅎㅎ
실제 위와 같이 쓰는 경우도 봤지만 매번 저 사이트에서 이미지를 불러와 값을 얻어야 한다.
아래는 위 값이 어떻게 얻어지는지에 대해 기술한다.
♣ BMP Color Table
BMP 정보에 Color Table 값이 있는데 이 값에 따라 0 -> 1 또는 1 -> 0 으로 변환시켜야 한다.
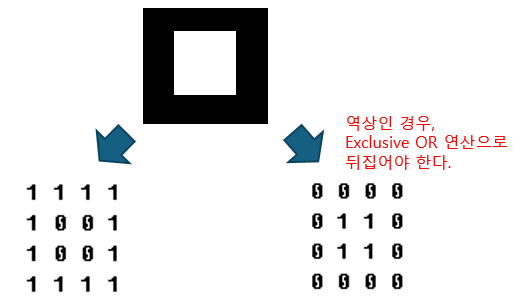
예를 들어 아래와 같은 사각형은,
Color Table 값에 따라 역상되어 저장될 수 있다. 이 경우, 0 -> 1로 바꿔주는 작업이 필요하다.
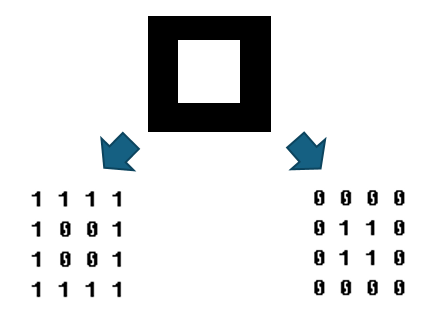
이게, 디자인팀으로부터 이미지를 받았을 때 역상되어 출력되어 우연히 발견한 경우인데,
디자이너에게 물어봐도 자기도 모른다는 답변만...
일단은 무식하게, Color Table 값으로 위와 같이 두가지로 저장될 수 있다고 이해하자.
♣ 1비트 BMP Raw Data
앞서 언급했듯이 비트 단위를 1비트로 두고 저장하면 실제 데이터는 비트 단위로 저장되게 된다.
하지만 파일은 바이트 단위로 저장된다.
이에 비트 단위 데이터가 어떻게 저장되는지에 대한 이해가 필요하다.
예를 들어 6 x 5 크기의 bmp 파일이 있다고 하자.
이 파일을 hex editor 로 열면 아래가 Data 영역이 된다.

Raw Data 만 나열하면 아래와 같다. 높이가 5이니 5줄로 표시될 것이다.
(BMP Data 는 역행으로 저장되므로 맨 윗줄이 맨 아래 저장된다. 맨 아랫줄은 맨 위에 저장됨)
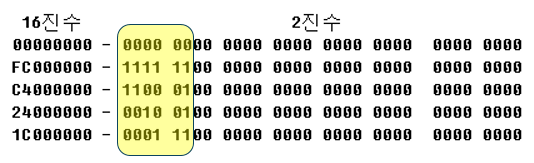
위에서 보는 것처럼 폭이 6 픽셀이지만 한줄은 32비트, 4바이트를 차지하고 26비트가 0으로 Padding 되었다.
만약 크기가 30 x 5 이면 어떨까?
한줄은 32비트 (4Bytes) 가 사용되며 우측 2비트는 Padding 되었다.
이제 추측이 가능하다.
이미지의 폭은 32비트 단위로 나뉘어지며 남는 비트는 0 으로 padding 되는 것을~
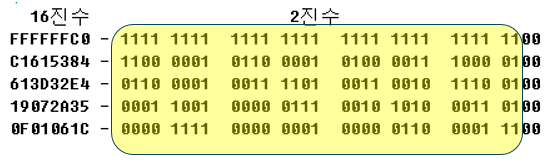
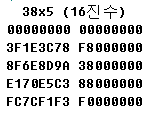
이를 위해 38 x 5 짜리의 Raw Data 를 확인해 보면 아래처럼 64비트, 8바이트로 확장됨을 확인할 수 있다.
♣ GFA 값 생성
Zebra 문서에 따르면 GF Command 는 아래처럼 정의된다.

a : Compression Type
A : ASCII Hex 값. 위 예제처럼 Hex 텍스트로 읽을 수 있는 값. 우리가 사용하는 값
B : Binary - 말그대로 binary 그 자체. 메모장으로 열면 깨져서 보인다.
C : Compressed Binary - 위 binary 를 압축한 것 같다. 자세한 건 문서 참조.
b : Binary byte count
c : Graphic field count
d : bytes per row
data : data
이 절에선 b,c,d 값 의 계산을 다룬다.
글 앞부분에서 Labelary 사이트에서 "Add Image" 로 bmp 파일을 불러오면
자동으로 GFA 코드가 생성되는 것을 확인할 수 있었다.
bmp 이미지 크기별로 생성되는 GFA 코드는 아래와 같다.
(Data 영역은 나중에 다룰 것이며, 여기선 b,c,d 값에 중점을 둔다. )
| 이미지 크기 (Pixel) | ^GFA 코드 | b (Binary Byte Count) |
c (Graphic Field Count) |
d (bytes per row) |
| 6 x 5 | ^GFA,5,5,1, | 5 | 5 | 1 |
| 14 x 5 | ^GFA,10,10,2 | 10 | 10 | 2 |
| 22 x 5 | ^GFA,15,15,3 | 15 | 15 | 3 |
| 24 x 5 | ^GFA,15,15,3, | 15 | 15 | 3 |
| 30 x 5 | ^GFA,20,20,4 | 20 | 20 | 4 |
| 38 x 5 | ^GFA,25,25,5 | 25 | 25 | 5 |
일단 눈대중으로 확인할 수 있는 내용은,
- b,c 값을 동일하다. ( 아마도 GFB, GFC 인 경우, 두 값이 다를 것 같다.)
- d 값은 이미지의 폭을 8 로 나눈 몫이다. (int)width / 8
그렇다면 b 값만 구하면 된다.
우선, 이미지 폭 (width) 의 정의를 아래처럼 3가지로 나눌 수 있다. (용어는 내마음대로 정함)
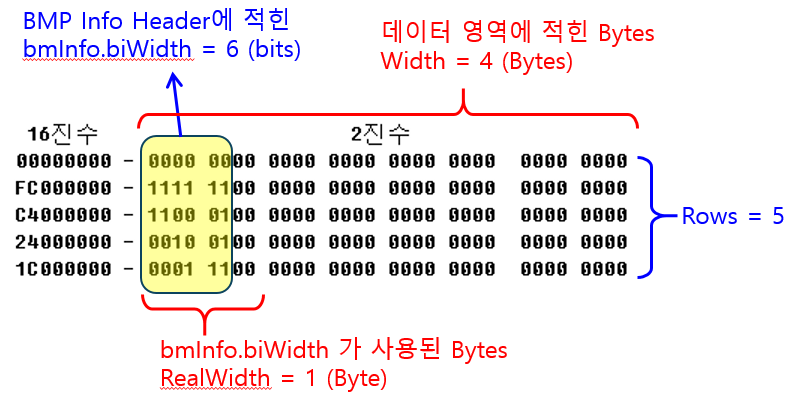
이 때, b,d 값은
- b = RealWidth * Rows = 1 * 5 = 5
- d = RealWidth = 1
가 된다.
만약 30 x 5 픽셀이라면, 아래처럼 계산될 것이다.
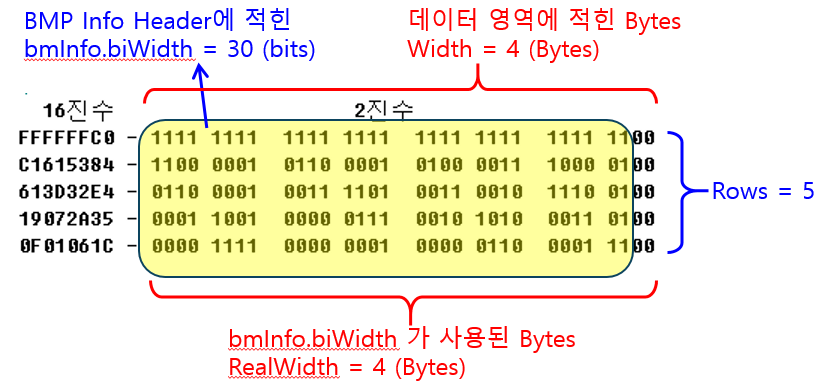
이 때 b,d 값은
- b = RealWidth * Rows = 4 * 5 = 20
- d = RealWidth = 4
가 된다.
♣ GFA 옵션 b,c,d 계산
그림상으로는 위와 같이 계산이 되는데 실제 코드상에선 아래처럼 구할 수 있다.
우선, BMP 헤더 구조체에서 구할 수 있는 정보는 아래와 같다.
(아래 구조체 변수는 윈도우 기준이다.)
BITMAPFILEHEADER bmFile ;
- bmFile.bfSize : 파일 크기
- bmFile.bfOffBits : 파일에서 Raw Data 가 시작되는 위치
BITMAPINFOHEADER bmInfo ;
- bmInfo.biWidth : 실제 이미지의 가로(폭) 사이즈
- bmInfo.biHeight : 실제 이미지의 세로(높이, rows) 사이즈
이 때, 앞절 그림의 4가지 값은 아래처럼 구할 수 있다.
- bmInfo.biWidth = bmInfo.biWidth
- bmInfo.biHeight = bmInfo.biHeight
- Width = (bmFile.bfSize - bmFile.bfOffBits) / bmInfo.biHeight
- RealWidth = (bmInfo.biWidth + 7) / 8
이제 최종으로 GFA 명령어의 옵션 b,c,d 값은 아래처럼 계산된다.
- b = RealWidth * bmInfo.biHeight
- c = b
- d = RealWidth
♣ GFA 옵션 data 얻기 - 정상과 역상
앞서 언급했듯이 Color Table 에 따라 Raw Data 는 아래처럼 정상 또는 역상으로 저장되어 있다.
역상인 경우, 1->0, 0->1 로 뒤집어줘야 한다. (Exclusive OR )
♣ GFA 옵션 data 얻기 - 정상
아래는 14 x 5 크기의 정상 Raw Data 영역이다.
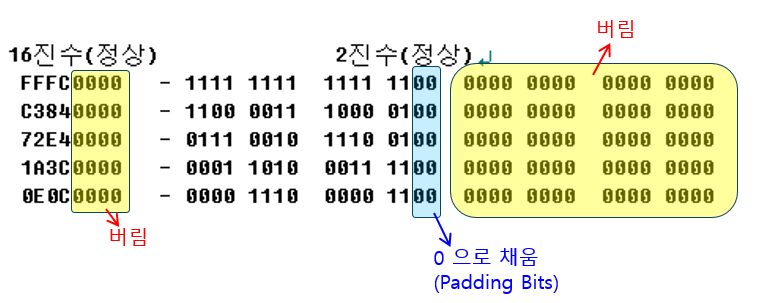
위의 경우, Real Width = 2 Bytes 만큼만 취하고 나머지는 버린다.
크기가 14 이므로 16 - 14 = 2 bits 만큼 0 으로 채운다.
그리고 남은 데이터가 GFA 의 마지막 data 옵션에 들어간다.
위 그림의 경우,
- FFFCC38472E41A3C0E0C
가 최종 data 가 된다.
이 data 만으로도 이미지를 출력할 수 있지만 압축하여 data 의 길이를 줄일 수 있다.
이는 저~ 아래에서 다룬다.
위 데이터값을 사용하여 아래와 같이 ZPL 을 구성할 수 있다.
Labelary 에서 정상적으로 bitmap 을 출력하는 것을 확인할 수 있다.
| ZPL | 라벨 이미지 |
| ^XA ^FO10,10 ^GFA,10,10,2,FFFCC38472E41A3C0E0C ^XZ |
 |
♣ GFA 옵션 data 얻기 - 역상
위 이미지의 역상 Raw Data는 아래와 같다.
정상인 경우와 마찬가지로 우측 2 Bytes 를 버린다.
그리고 정상과는 달리 1로 Padding bits 를 채운다.
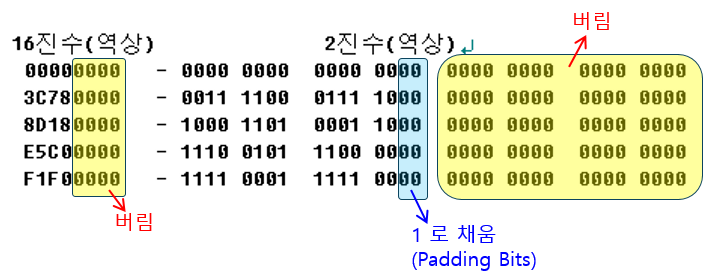
데이터 버리고 Padding Bits 를 1로 채우면 아래와 같다.
그리고 Exclusive OR (XOR) 연산을 하면 정상과 같은 데이터를 얻을 수 있다.
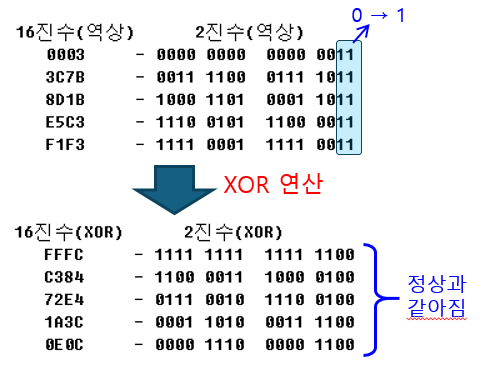
이 후, 정상과 같은 절차로 GFA 를 생성할 수 있다. (정상과 같으므로 생략)
♣ Raw Data 압축
테스트를 위해 아래와 같이 임의의 1bits 짜리 bmp 파일을 생성했다.
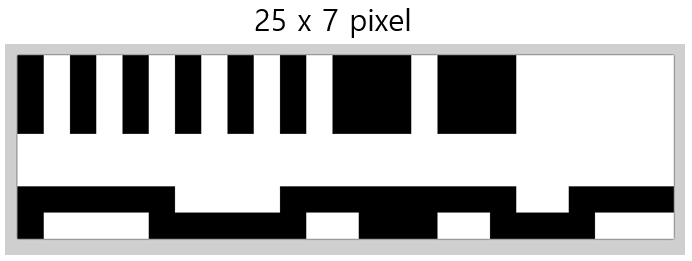
그리고 위 절차와 같이 GFA 명령어용 data 를 추출하면 아래와 같다.
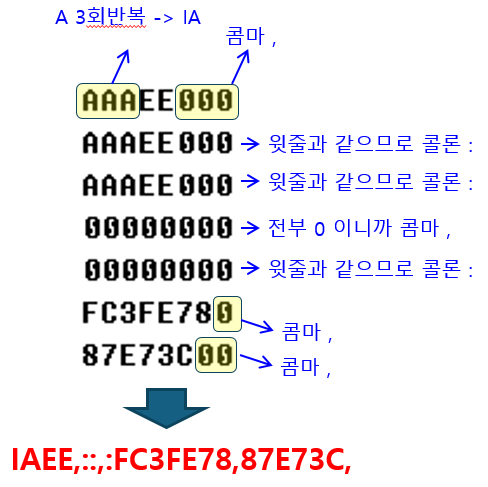
- AAAEE000AAAEE000AAAEE0000000000000000000FC3FE78087E73C00
그런데 위 이미지 파일을 labelary 사이트에서 불러오면 data 영역이 아래와 같다.
- IAEE,::,:FC3FE78,87E73C,
두 결과는 같다.
즉, 위 56글자를 아래 24글자로 줄일 수 있다는 것이다.
규칙은 아래와 같다.
■ 연속된 글자
연속된 글자는 "갯수 + 글자" 로 줄인다. 예를 들면,
| Raw Data | 압축 | 설명 |
| 444444 | L4 | L=6번 반복 -> 4를 6번 찍음 |
| DDD | ID | I=3번 반복 -> D를 3번 찍음 |
| C -> 340 개 연속 | wC | w=340번 반복 |
| C -> 342개 | wHC | w=340번 + H=2번 만큼 반복 |
| F -> 495개 | zFjUF | z(400) + j (80) + U (15) = 495 개 |
반복 횟수를 나타내는 앞글자는 아래처럼 정의된다.
HEX 값에 사용되는 A~F 를 벗어난 값으로 세팅됨을 알 수 있다.
G, H 의 경우, 20회 이상인 경우에 사용된다.
반복횟수가 1인 경우 -> 압축하면 손해 (1글자 -> 2글자)
반복횟수가 2인경우 -> 압축의 의미없음 (2글자 -> 2글자)
400개 이상인 경우, 400개에서 끊는다.
| G : 1 회 (20회 이상) H : 2 회 (20회 이상) I : 3 회 J : 4 회 K : 5 L : 6 M : 7 N : 8 O : 9 P : 10 |
Q : 11 회 R : 12 회 S : 13 회 T : 14 U : 15 V : 16 W : 17 X : 18 Y : 19 |
g : 20회 h : 40회 i : 60회 j : 80회 k : 100 l : 120 m : 140 n : 160 o : 180 p : 200 |
q : 220 회 r : 240 s : 260 t : 280 u : 300 v : 320 w : 340 x : 360 y : 380 z : 400 |
■ 한 줄 끝까지 0인 경우,
예를 들어 Data의 뒷부분이 0 이면 ,(콤마) 로 치환할 수 있다.
| Raw Data | 압축 | 설명 |
| DA0000 | DA, | |
| 000000 | , | 한줄 전체가 ',' 로 압축됨 |
| 555F00 | I5F, | 5 세번 + 'F' + ',' |
■ 한 줄 끝까지 F인 경우,
위와 맥락이 같으며 뒷부분이 F이면, ! (느낌표) 로 치환할 수 있다.
내용은 위 0 과 동일하다.
■ 윗 줄과 같은 경우
윗줄과 내용이 같으면 : (콜론) 으로 치환할 수 있다.
| Raw Data | 압축 | 설명 |
| DA0000 DA0000 |
DA,: | 두번째 줄이 윗줄과 같으므로 ':' 으로 압축됨 |
| DA0000 DA0000 DA0000 DA0000 |
DA,::: | 뒤에 세줄 반복이므로 ':' 를 세번 사용하여 표시함. |
위와 같이 압축기법을 적용하면, 위 25x7 예제 BMP 파일의 raw data 는 아래처럼 압축될 것이다.
최종으로 얻은 값은 Labelary 사이트에서 생성된 값이랑 일치함을 확인할 수 있다.
♣ BMP 파일 생성
테스트를 위해 BMP 파일을 하나 만든다.
- Visual Studio 2017 Express
- Windows API 기반 C++
- 콘솔 환경에서 컴파일하여 결과를 얻을 수 있다.
- main() 함수에서 test.bmp 를 본인의 파일로 적절히 수정한다.
#include <cstdio>
#include <string>
#include <list>
#include <map>
#include <windows.h>
using namespace std ;
int compressData(list<string>* pList)
{
list<string>::iterator pListIter ;
list<string>::iterator pListIter2 ;
pListIter2 = pList->end() ;
int flagFirst = 1 ;
// check data is same as above line
if(pList->size() > 1)
{
while(1)
{
pListIter2-- ;
pListIter = pListIter2 ;
pListIter-- ;
if(!pListIter->compare(*pListIter2))
*pListIter2 = ":" ;
if(pListIter == pList->begin())
break ;
}
}
// Check last data "0"
size_t pos ;
int p ;
for(auto& zpl : *pList)
{
pos = zpl.find_last_not_of("0") ;
// Skip if the last character is not "0"
if(zpl.back() != '0')
continue ;
p = (pos == string::npos) ? -1 : pos ;
zpl.replace(zpl.begin()+(p+1), zpl.end(), ",") ;
}
// Check last data "F"
for(auto& zpl : *pList)
{
pos = zpl.find_last_not_of("F") ;
// Skip if the last character is not "0"
if(zpl.back() != 'F')
continue ;
p = (pos == string::npos) ? -1 : pos ;
zpl.replace(zpl.begin()+(p+1), zpl.end(), "!") ;
}
// check ducplicated character.
list<pair<char, int> > listCount ;
list<pair<char, int> >::iterator listCountIter ;
int len, cnt ;
char prev, cur ;
for(auto& zpl : *pList)
{
string strOrg = zpl ;
len = zpl.length() ;
prev = 0;
cnt = 0 ;
listCount.clear() ;
for(int ii = 0; ii < len; ii++)
{
cur = zpl[ii] ;
if(cur == prev)
{
cnt++ ;
}
else // cur != prev
{
if(prev)
listCount.push_back(make_pair(prev, cnt)) ;
cnt = 1 ;
prev = cur ;
}
if(cnt == 400)
{
listCount.push_back(make_pair(cur, 400)) ;
cnt = 0 ;
}
if(ii == len-1 && cnt > 0 )
listCount.push_back(make_pair(cur, cnt)) ;
}
// printf("======= List Count ======\n") ;
int quotient, remainder ;
zpl.clear() ;
char ch1, ch20;
for(auto data : listCount)
{
// printf("%c - %d\n", data.first, data.second) ;
if(data.second <= 2)
{
zpl += data.first ;
if(data.second == 2)
zpl += data.first ;
continue ;
}
// 3 <= data.second <= 19
if(data.second < 20)
{
ch1 = 'G' + data.second - 1 ;
zpl += ch1 ;
zpl += data.first ;
continue ;
}
// 20 <= data.second <= 400
quotient = (int)data.second/20 ;
remainder = data.second % 20 ;
ch1 = (remainder > 0) ? 'G' + remainder - 1 : '0' ;
ch20 = 'g' + quotient - 1 ;
zpl += ch20 ;
if(remainder > 0)
zpl += ch1 ;
zpl += data.first ;
}
// printf("ORG : %s\n", strOrg.c_str()) ;
// printf("NEW : %s\n", zpl.c_str()) ;
}
return 1 ;
}
string genZPL_Bitmap(const char* szFile)
{
BITMAPFILEHEADER bmFile ;
BITMAPINFOHEADER bmInfo ;
unsigned char colorTable[4] ;
int flagInvert=0 ;
char szText[1024] ;
string strZpl ;
strZpl = "^XA" ;
strZpl += "^FO20,20" ;
sprintf(szText, "./%s", szFile) ;
FILE* fp = fopen(szText, "rb") ;
if(!fp)
{
printf("genBitmap File Error - %s\n", szText) ;
strZpl.clear() ;
return strZpl ;
}
fread(&bmFile, sizeof(BITMAPFILEHEADER), 1, fp) ;
fread(&bmInfo, sizeof(BITMAPINFOHEADER), 1, fp) ;
fread(colorTable, sizeof(colorTable), 1, fp) ;
printf("File : %s\n", szFile) ;
printf("bmFile.bfSize : %d\n", bmFile.bfSize) ;
printf("bmFile.biWidth : %d\n", bmInfo.biWidth) ;
printf("bmFile.biHeight: %d\n", bmInfo.biHeight) ;
printf("ColorTable : %02X %02X %02X %02X\r\n",
colorTable[0], colorTable[1], colorTable[2], colorTable[3]) ;
if(colorTable[0] * colorTable[1] * colorTable[2] < 0x800000)
flagInvert = 1 ;
printf("FlagInvert = %d\r\n", flagInvert) ;
fseek(fp, bmFile.bfOffBits, SEEK_SET) ;
printf("bmFile.bfOffBits = %d (0x%02X)\r\n", bmFile.bfOffBits, bmFile.bfOffBits & 0xff) ;
printf("bmInfo.Width = %d\r\n", bmInfo.biWidth) ;
int width = (bmFile.bfSize - bmFile.bfOffBits)/bmInfo.biHeight ;
int realWidthByte = (bmInfo.biWidth + 7) / 8 ;
printf("Width ; %d\r\n", width) ;
printf("Real Width Byte; %d\r\n", realWidthByte) ;
int imageSize = realWidthByte * bmInfo.biHeight ;
printf("GFA Image Count : %d\r\n", imageSize ) ;
sprintf(szText, "^GFA,%d,%d,%d,", imageSize, imageSize, realWidthByte) ;
strZpl += szText ;
list<string> listRow ;
list<string>::iterator listRowIter ;
string strRow ;
char szTemp[32] ;
int nTemp ;
unsigned char shValue ;
for(int ii = 0; ii < bmInfo.biHeight; ii++)
{
strRow.clear() ;
for(int jj = 1; jj <= width; jj++)
{
fread(szTemp, 1, 1, fp) ;
if(jj > realWidthByte)
continue ;
if(jj == realWidthByte)
{
nTemp = bmInfo.biWidth & 0x07 ;
shValue = 0xff ; // case of flagInvert == 1 72x72
shValue = (nTemp == 1) ? 0x80 : shValue ;
shValue = (nTemp == 2) ? 0xC0 : shValue ;
shValue = (nTemp == 3) ? 0xE0 : shValue ;
shValue = (nTemp == 4) ? 0xF0 : shValue ;
shValue = (nTemp == 5) ? 0xF8 : shValue ;
shValue = (nTemp == 6) ? 0xFC : shValue ;
shValue = (nTemp == 7) ? 0xFE : shValue ;
if(flagInvert)
szTemp[0] |= (shValue ^ 0xff) ;
else
szTemp[0] &= shValue ;
}
if(flagInvert)
szTemp[0] ^= 0xff ;
szTemp[1] = '\0' ;
sprintf(szText, "%02X", szTemp[0] & 0xff) ;
strRow += szText ;
}
listRow.push_front(strRow) ;
}
fclose(fp) ;
#if 1
// compress Data
printf("********** Before compress data **********\n") ;
for(auto& pData : listRow)
printf("%s\n", pData.c_str()) ;
compressData(&listRow) ;
printf("********** Aftercompress data **********\n") ;
for(auto& pData : listRow)
printf("%s\n", pData.c_str()) ;
#endif
// Add Raw Data
listRowIter = listRow.begin() ;
for(; listRowIter != listRow.end(); listRowIter++)
strZpl += *listRowIter ;
strZpl += "^FS";
strZpl += "^XZ";
return strZpl ;
}
int main()
{
string strZpl ;
const char* szFile = "./test.bmp" ;
strZpl = genZPL_Bitmap(szFile) ;
printf("ZPL : %s\n", strZpl.c_str()) ;
#if 1
// copy ZPL to ClipBoard
if(!OpenClipboard(NULL))
{
printf("Failed OpenClipboard()\r\n") ;
return 1;
}
if(!EmptyClipboard())
{
printf("Failed EmptyClipboard()\r\n") ;
return 1 ;
}
int len = strZpl.length() ;
HGLOBAL hGlobal = GlobalAlloc(GMEM_MOVEABLE, len + 1) ;
char* pClip = (char*)GlobalLock(hGlobal) ;
strcpy(pClip, strZpl.c_str()) ;
GlobalUnlock(hGlobal) ;
if(!SetClipboardData(CF_TEXT, hGlobal))
{
printf("Failed SetClipboardData()\r\n") ;
}
CloseClipboard() ;
#endif
return 1 ;
}
'삽질미학 > 잡동사니' 카테고리의 다른 글
| Python과 OpenSSL 간 RSA PKI 테스트 (0) | 2020.04.27 |
|---|---|
| 단색 Bitmap 파일을 ZPL GFA 코드로 변환하기 (3) | 2018.10.01 |
| [ZPL] ZPL 로 특수문자 출력하기. (0) | 2018.07.11 |
| [ZPL] QRCode 출력 시, 상단에 갭이 생기는 경우 (0) | 2018.07.11 |
| svn ignore 사용하기. (svn 특정 파일, 디렉토리 무시하기) (0) | 2017.12.12 |



